2 Lexical Analysis¶
说明
本文档仅涉及部分内容,仅可用于复习重点知识
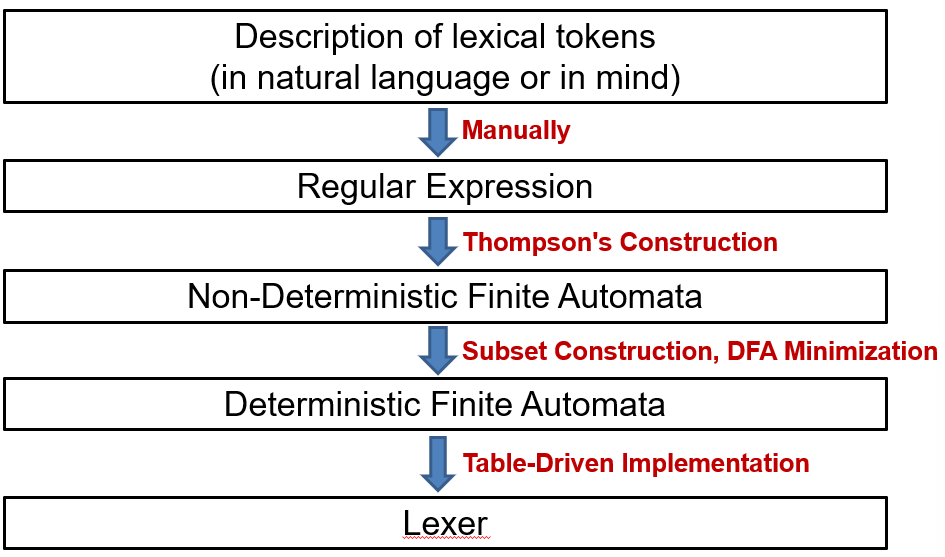
1 Lexical Token¶
词法单元:词法分析的结果。它是源代码中最小的、有独立意义的单位。在这里,词法单元就充当了终结符的角色,语法分析器会直接处理这些词法单元,而不会关心它们内部的单个字符

非词法单元:
- 注释
- 预处理指令:
#include<stdio.h> - 宏定义
- 空格、制表符和换行
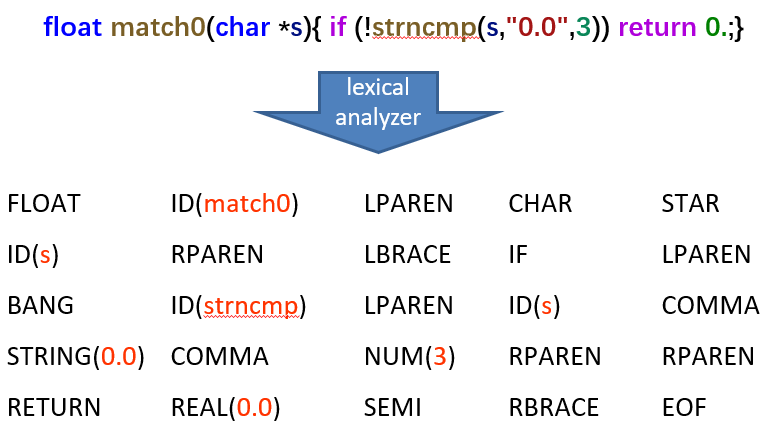
2 Regular Expression¶

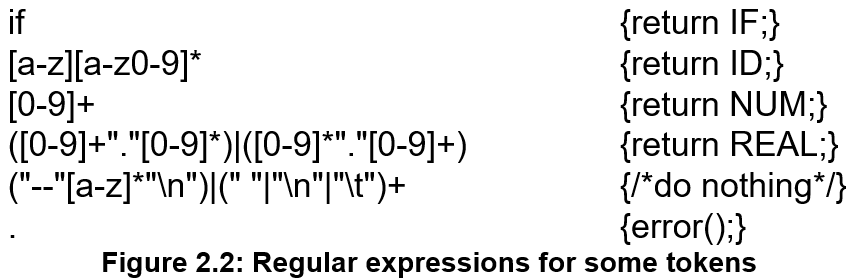
当输入字符串可能被多种规则匹配时,两条重要的歧义消除规则决定了最终的选择:
- longest match:从输入的开头开始,能够与任意正则表达式匹配的最长初始子字符串,将被作为下一个词法单元
- rule priority:对于某一个特定的最长初始子字符串,第一个能够匹配它的正则表达式决定了它的词法单元类型。这意味着编写正则表达式规则的顺序非常重要
对于 if8 来说,最长匹配规则会将 if8 视作一个 token,因此 if8 被识别为 ID
对于 if 来说,关键字规则 if 和标识符规则都能匹配,但关键字规则在前,所以会采用前者,将 if 识别为 IF
3 Finite Automata¶
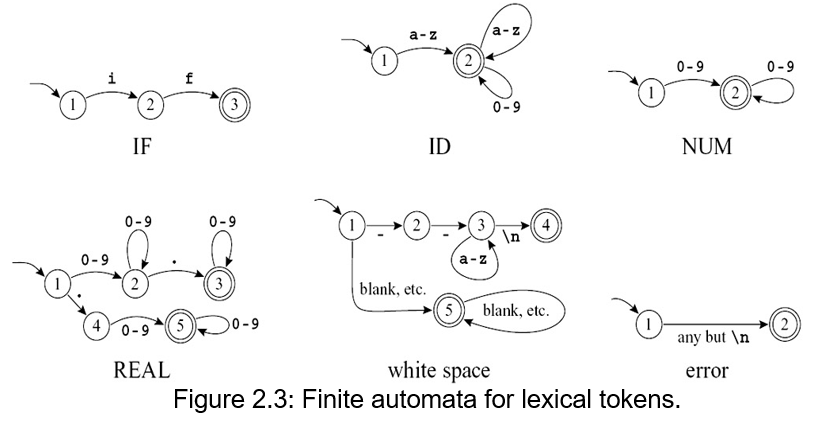
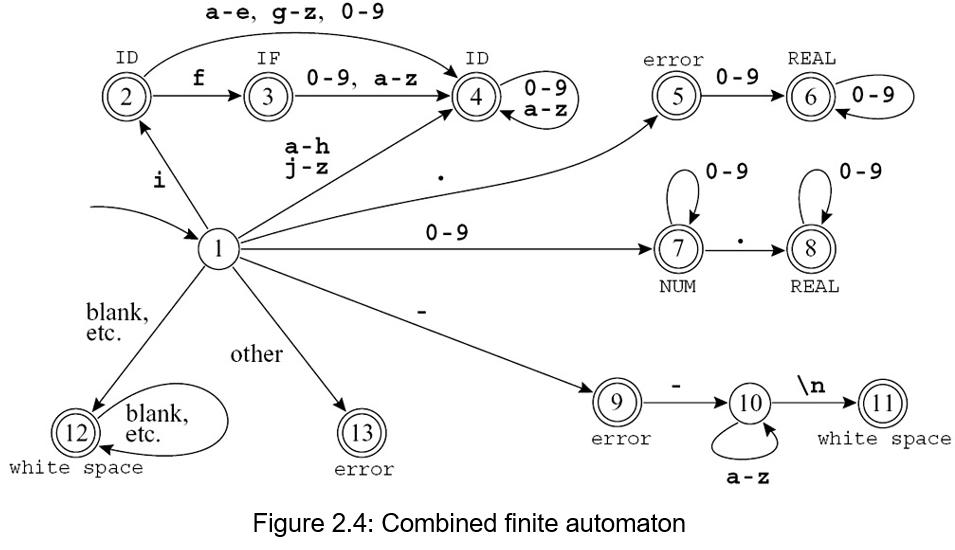
有了 DFA,我们就可以生成出 lexer(词法分析器)。使用一个 transition matrix

词法分析器如何做到识别最长匹配:词法分析器通常使用一个状态机,当它逐个读取输入字符并转换状态时,它会记录关键信息,维护两个变量来记住到目前为止找到的最长的有效 token
- Last-Final:记录最近一次进入一个 最终状态(表示识别出一个完整 token,在 DFA 上表现为一个终止状态)的状态编号
- Input-Position-at-Last-Final:记录当时读取到输入字符串的哪个位置

4 Nondeterministic Finite Automata¶
从 regular expression 转换到 NFA:
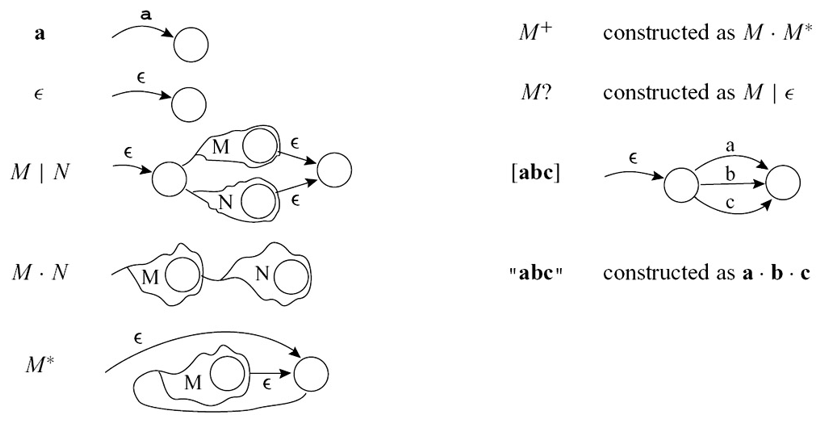
从 NFA 转换到 DFA:计算理论 - 2 Finite Automata - 2 Nondeterministic Finite Automata
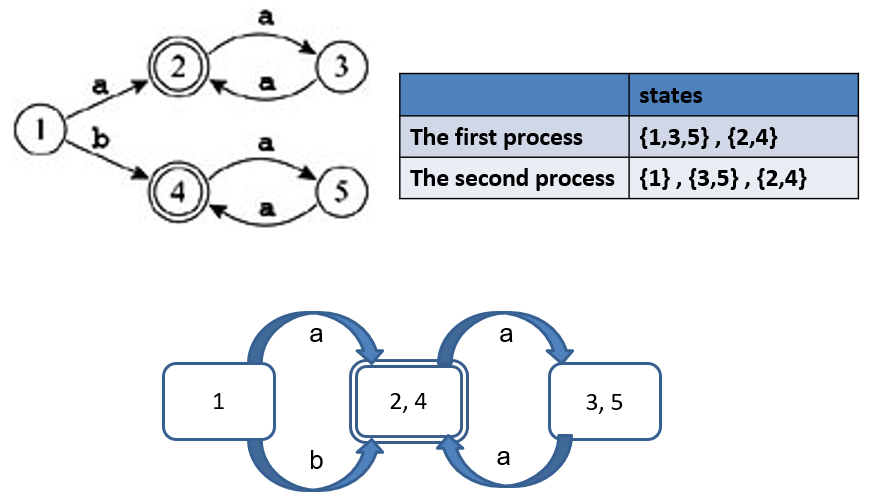
化简 DFA 成 minimum-state DFA:
- 首先将所有状态分成两组:终止状态和非终止状态。因为终止状态和非终止状态肯定不等价
-
细化分组:重复此步骤,直到无法再进行任何分裂
- 对于组内的两个状态 s 和 t,如果在每一个可能的输入符号下,它们跳转到的状态都属于同一个分组,那么 s 和 t 目前看起来是等价的,可以暂时留在同一组
- 如果存在某个输入符号,使得 s 和 t 跳转到的状态属于不同的现有分组,那么 s 和 t 就是不等价的,必须将这个组分裂成更小的组
-
此时,每个分组内部的所有状态对于所有输入符号的行为都完全一致。据此构建最小化 DFA
5 Lex¶
Lex 程序的输入是一个文本文件,通常以 .l 为后缀。这个文件主要包含两部分信息:
- 正则表达式:用来描述词法规则
- actions:与每个正则表达式相关联的 C 代码片段。当词法分析器识别出某个正则表达式匹配的字符串时,就会执行对应的动作
Lex 处理输入文件后,会生成一个名为 lex.yy.c 的 C 源代码文件。这个文件的核心是一个名为 yylex 的函数。yylex 函数的本质是一个由表格驱动的 DFA 的实现。这意味着 Lex 已经将用户提供的正则表达式转换成了一个高效的状态机,并嵌入到了生成的代码中。它的行为就像一个 getToken 过程:每当被调用时,它就从输入流中读取字符,运行这个状态机,找到匹配的最长字符串,然后执行相应的动作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 | |